claude-code - 💡(How to fix) Fix [FEATURE] Built-in token optimization: read caching, test output filtering, large file blocking [2 comments, 3 participants]
ON THIS PAGE
Recommended Tools
×6Utilities matched from this issue’s tags and category — try them while you read without losing context.
GitHub issue graph ai analysis
Paste a GitHub issue URL. We fetch that issue, discover linked issues from bodies/comments/timeline, collect linked pull requests, and produce a structured English report.
The report is written in English Markdown for sharing and archival.
Helpful · Quick feedback
RAW_BUFFERClick to expand / collapse
Preflight Checklist
- I have searched existing requests and this feature hasn't been requested yet
- This is a single feature request (not multiple features)
Problem Statement
Claude Code consumes tokens every time it reads a file, runs a test, or checks logs. In a typical coding session, I observed several wasteful patterns:
-
Redundant file reads: The same file gets read 3-5 times per session (before edit, after edit, during review, when referencing). Each re-read consumes tokens for identical content that Claude already has in context.
-
Verbose test output: Running
pytestorjestproduces 200+ lines of output (progress dots, warnings, capture logs, fixture setup), but Claude only needs the session start, failures, and summary to make decisions. -
Unbounded log output: Commands like
cat app.logordocker logsdump entire files into the context when the last 100 lines would suffice. -
Large file consumption: Files with 1000+ lines get read in full even when Claude only needs a specific section, consuming massive amounts of tokens unnecessarily.
These patterns compound in longer sessions and lead to faster context exhaustion and higher token costs.
Proposed Solution
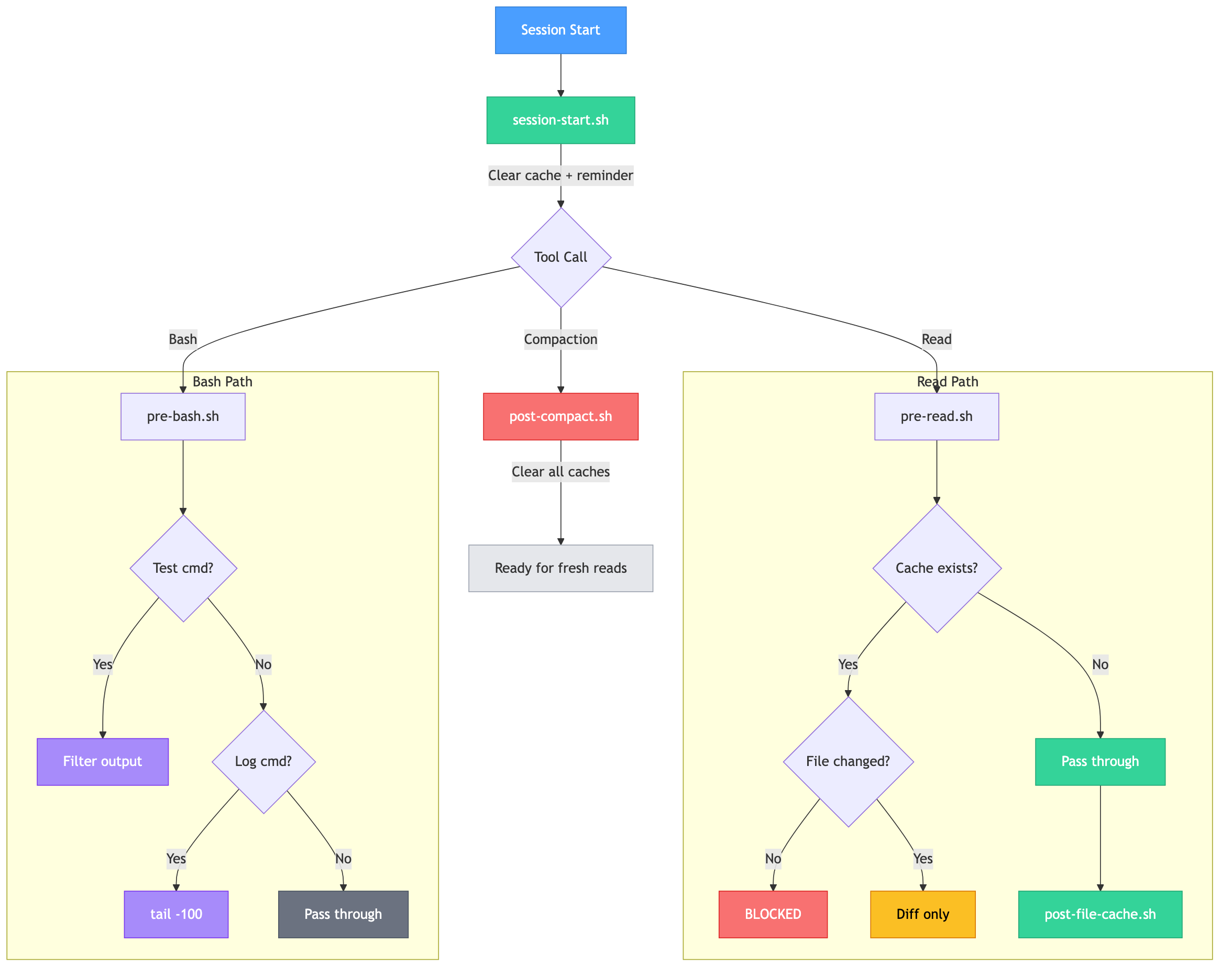
I built a set of 6 hook scripts that solve these problems using Claude Code's existing hook system. The hooks work transparently without changing how the user interacts with Claude Code:
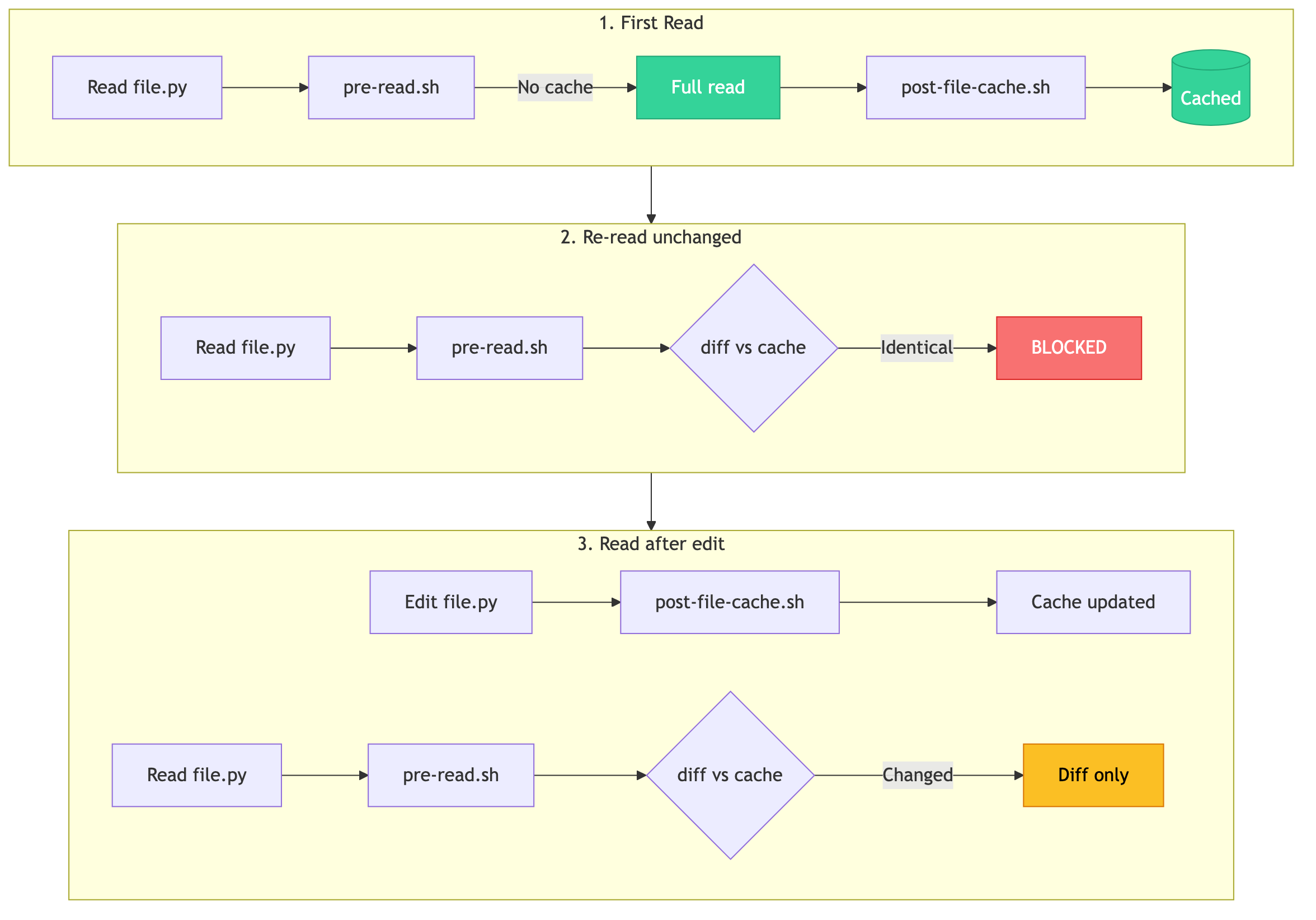
Read caching (pre-read.sh + post-file-cache.sh):
- First read: passes through normally, caches a snapshot
- Re-read (unchanged): blocked entirely with "File unchanged" message
- Re-read (after edit): returns only the unified diff, not the full file
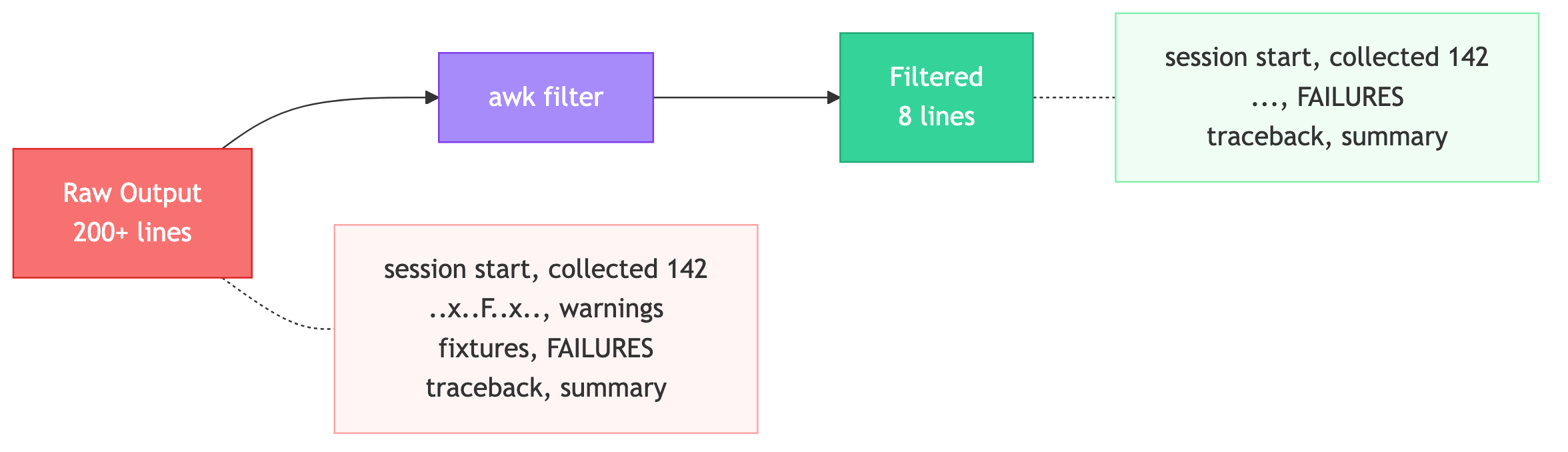
Test output filtering (pre-bash.sh + pre-bash.helper.filter.sh):
- Detects test commands (pytest, jest, vitest, Django test)
- Pipes output through an awk filter that extracts only: session start, collected count, failures, errors, and final summary
- 200+ lines become ~8 lines
Log output limiting (pre-bash.sh):
- Detects log commands without existing truncation (cat *.log, docker logs, journalctl)
- Automatically appends
| tail -100
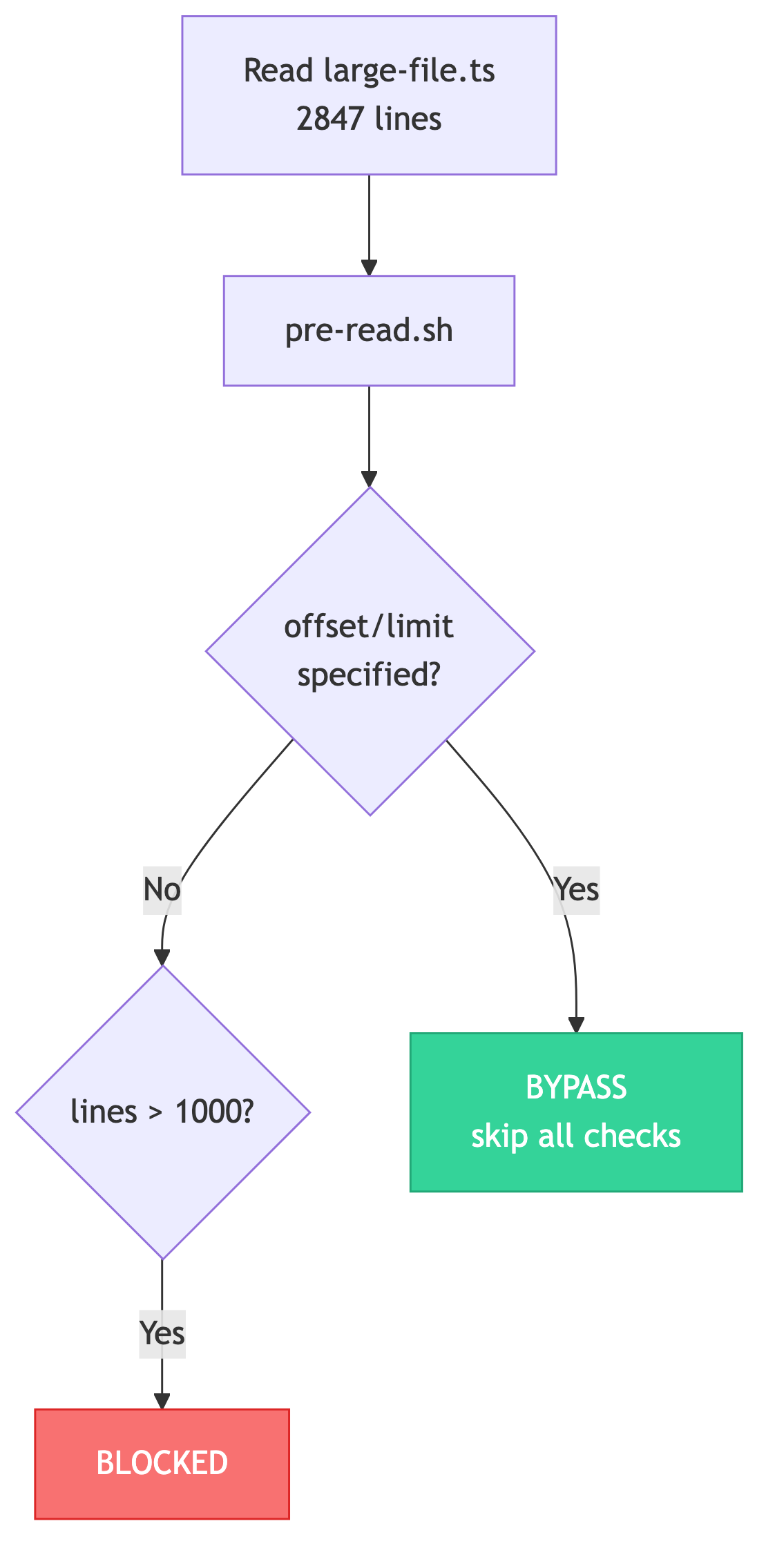
Large file blocking (pre-read.sh):
- Files over 1000 lines are blocked unless offset/limit is specified
- Forces targeted reads instead of full-file consumption
Compaction awareness (post-compact.sh + session-start.sh):
- Clears read cache after context compaction (since Claude loses detailed file content)
- Cleans up stale caches older than 7 days
I'd love to see some form of these optimizations built into Claude Code natively, or at minimum, included as an official example/recipe in the docs.
Alternative Solutions
I'm currently using these hooks via a standalone repository with a one-command installer:
Repository: https://github.com/soonswan-study/claude-code-thrifty
The installer symlinks hooks to ~/.claude/hooks/ and merges config into ~/.claude/settings.json. It works well but requires manual installation and jq as a dependency.
Session Lifecycle:
Read Cache Flow:
Test Output Filter:
Large File Protection:
Priority
Medium - Would be very helpful
Feature Category
Performance and speed
Use Case Example
Example scenario:
- I'm working on a Django backend with 50+ files
- I ask Claude to fix a bug in
services/payment.py(400 lines) - Claude reads the file, edits it, then reads it again to verify — that's 800 lines of tokens for one read of identical content
- I then ask Claude to run tests:
pytest tests/test_payment.py -vwhich outputs 150 lines, but only 8 lines matter (collected count + 1 failure + summary) - With read caching, the second read is blocked (0 tokens). With test filtering, 150 lines become 8 lines
- Over a 30-minute session with multiple files and test runs, this compounds to significant token savings
Additional Context
- Repository with full implementation: https://github.com/soonswan-study/claude-code-thrifty
- Detailed per-hook documentation: https://github.com/soonswan-study/claude-code-thrifty/blob/main/docs/HOOKS.md
- Requirements:
jqfor JSON parsing,bash4.0+ - The hooks are session-scoped (each session gets its own cache directory), so parallel sessions don't interfere
- All hooks are non-invasive: partial reads (offset/limit), binary files, and first reads always pass through unchanged
extent analysis
TL;DR
Implementing hook scripts for read caching, test output filtering, log output limiting, and large file blocking can significantly reduce token consumption in Claude Code.
Guidance
- Review the proposed hook scripts in the
claude-code-thriftyrepository to understand how they address redundant file reads, verbose test output, unbounded log output, and large file consumption. - Consider integrating these optimizations into Claude Code natively or including them as official examples in the documentation to improve performance and reduce token costs.
- Evaluate the use of
jqfor JSON parsing andbash4.0+ as requirements for the hook scripts. - Test the hook scripts in a controlled environment to verify their effectiveness in reducing token consumption before implementing them in production.
Example
# pre-read.sh example
if [ -f "$cache_file" ] && ! $edited; then
echo "File unchanged"
exit 0
fiThis example shows how the pre-read.sh script checks if a file has been edited before reading it, and if not, returns a "File unchanged" message to block the read and conserve tokens.
Notes
The proposed solution relies on the existing hook system in Claude Code, which may have limitations or compatibility issues with certain versions or configurations. Additionally, the effectiveness of the hook scripts may vary depending on the specific use case and workflow.
Recommendation
Apply the workaround by using the claude-code-thrifty repository and its hook scripts to optimize token consumption, as integrating these optimizations into Claude Code natively may require significant development and testing efforts.
Vote matrix · Quick signals
Still need to ship something?
×6Another batch ranked right after the header list — different links, same matching logic.
TRENDING
- Feature Request: Configurable per-minute rate limiting (RPM) for models to prevent 429 errors
- Android: Hermes App + Termux install share ~/.hermes and cause silent permission loops
- hermes update emits unicode-animations ANSI demo in non-interactive logs
- hermes update downgrades aiohttp from 3.13.4 to 3.13.3
- npm install warns about deprecated @babel/plugin-proposal-private-methods
- DingTalk inbound media URLs are skipped as unreadable native image paths
- fix(dashboard): ChatPage clears header action buttons on ALL pages, not just Sessions
- [Bug]: check_web_api_key() hardcodes built-in backends — third-party web search plugins silently disabled
- Hermes Web UI 修复经验:GatewayManager 补丁、进程 D 状态、数据库升级问题
- Telegram gateway can silently drop turn after /stop with response=0 chars while internal work continues
- Bug Report: v0.14.0 上下文污染 — 历史回复碎片回注到新请求
- Bug: hermes skills search table truncates Identifier column — install fails with copied value
- [skills-index-watchdog] Skills index is stale or degraded (degraded)
- Discord approval embed not rendering on web/mobile — embed data present in API but invisible
- Idea: Discord voice-channel participation / opt-in auto-join mode
- [Feature]: Claude Code--ultrawork
- build-arm64 job deterministically fails on cold cache (Azure SAS token expires mid-build)
- [Enhancement] computer_use: action=type should fall back to key events for terminal emulators (Ghostty/Terminal.app/iTerm2)
- Feature Request: Session Recovery on Temporary Provider Outage
- [Bug]: Hermes dashboard not working on NixOS (container)
- [Feature]: Add option to ignore @all/@everyone mentions in Feishu group chats
- QQ Bot WebSocket 频繁断开:长时间工具执行阻塞 asyncio 事件循环导致心跳超时
- patch tool: new_string escape sequences (\t) get written literally
- Feature Request: i18n / 多语言支持(国际化)
- Bug: web_crawl schema lets models auto-guess "instructions" instead of asking the user via clarify
- feat: `!command` prefix for direct shell execution (like Claude Code)
- Expose currently-running cron jobs via /api/jobs (or new endpoint)
- [Bug]: Kanban parent-child handoff: scratch workspace GC destroys artifacts before child can read them
- [Bug, Windows] hermes gateway restart loses session context — planned_stop_marker not written before SIGTERM
- [Bug]: Codex→DeepSeek fallback sends assistant turns without reasoning_content → HTTP 400 (require-side cross-provider failover)
- [Bug]: Update got stuck half way, reboot it, then ModuleNotFoundError: No module named 'hermes_cli'
- Kanban dispatcher corrupt-board handling and multi-profile gateway ownership ambiguity
- Gateway can resend a short fallback message when the real final Telegram response was already delivered
- [BUG] Bedrock: Fix 'Invalid API Key format' for presigned URL tokens
- Secret redaction corrupts code syntax in tool output (write_file, execute_code, terminal)
- Unable to connect Ollama Cloud with Pro Subscription to Hermes
- feat: fuzzy substring matching for /skill autocomplete
- PRD: Autonomous market-impact prediction briefing system
- Kanban dashboard should support task/card deep links
- [Feature] Native Feishu CardKit Streaming: consolidate best-in-class implementations
- [Feature]: Inject mental model into context when using Hindsight
- Interactive CLI hides tool output despite display.tool_progress=all, and hermes chat -v does not restore it
- fix(api_server): _handle_responses drops text.format JSON schema — structured output constraints silently ignored
- state.db FTS corruption goes undetected — no integrity check, no repair path
- bug: fallback routing can select text-only models for image requests and hide the primary failure
- feat(kanban): persist worker session_id per run and pass --resume on respawn after unblock
- feat(kanban): support GitHub/OMO lifecycle bridge for Xiyou-style automation
- Expose update-safe TUI/composer hooks for voice transcript and composer events
- Hide or configure voice transcript status rows in editable dictation mode
- [Feature]: Per-Tool / Per-Toolset Approval Policies
- Context compression creates orphan sessions missing from state.db
- messaging platform
- feat: Add read-only / silent monitoring mode for WhatsApp adapter
- double-.hermes path mismatch, the HOME env var leak, and the fallback-notification UX problem
- Bug: Plattform-Bundle name `hermes-yuanbao` in `agent.disabled_toolsets` silently kills ALL tools in gateway path (Telegram + cron), CLI unaffected
- CLI /yolo (in-chat) does not bypass dangerous command approvals — env var freeze + missing enable_session_yolo call
- OpenAI Codex provider crashes with "'NoneType' object is not iterable" (HTTP None)
- DEEPSEEK_API_KEY blocked by env blocklist in gateway process — cron jobs fail with deepseek provider
- fix(feishu): Card action callback routing issues - invalid message_id and unrecognized /card command
- Discord plugin: profiles without explicit `discord:` block silently get `require_mention=true` + `auto_thread=true` (regression in cc8e5ec2a)
- [Bug]: DISCORD_ALLOWED_ROLES ignored by gateway _is_user_authorized — role-authorized users get 'Unauthorized user' rejection
- [Bug]: /new, /clear, and /reset commands freeze the terminal session
- openai-codex subscription backend returns HTTP 200 with response.output=None, causing Slack/cron failures
- RFC: Centralized Model/Provider Registry
- bug: openai-codex provider — TypeError: 'NoneType' object is not iterable on every request (gpt-5.5)
- [Feature]: Source-aware instruction gate — architectural mitigation for indirect prompt injection
- Named custom provider stale_timeout_seconds ignored because runtime provider is normalized to `custom`
- guard test (ignore)
- [Feature]: per-platform LLM request_overrides (extra_body / reasoning_effort / service_tier)
- One-shot smoke: add Flue-backed orchestration fixture
- Gateway should not treat stale Codex app-server progress as final response after post-tool silence
- `docker_run_as_host_user: true` breaks bundled skills: Hermes home is mounted into `/root/.hermes` but the container runs as a non-root user (`HOME=/home/pn`)
- [Bug]: gateway api_server streaming bypasses server-side tool-call loop when chat_template_kwargs.enable_thinking=false (model emits tool name as plain text)
- [Feature]: Pre-install python-telegram-bot in Umbrel Hermes Docker image
- YouTube Shorts filter not working in youtube-content skill
- v0.15.0 PyPI release breaks ALL platforms — plugin.yaml manifests missing from package
- RFC: On-demand tool/skill/MCP discovery — decouple schema registration from process lifecycle
- Pixshelf: local-first stock photo workflow command center
- [Bug]: baoyu infographic skill should not silently bypass image_generate
- Pixshelf v1.5: manual submission tracking for stock agencies
- `hermes config set` silently accepts unknown keys, writing them where the runtime never reads
- Honcho memory prefetch hang on fresh CLI subprocess in v0.15.0 (regression from #27190)
- [Bug] v0.15.0 Docker image: stage2-hook.sh, main-wrapper.sh missing; container_boot module removed
- Feature: Reduce cache-read token overhead for DeepSeek providers — configurable cache_ttl, skills snapshot trimming, memory compaction
- Windows: three bugs from daily use (plugin discovery, gateway exit code, Unicode decode
- holographic memory: HRR silently degrades to FTS5 when numpy is missing
- Make max_tokens configurable for aux vision calls
- Conversation compression desynchronizes session ID between agent context and gateway routing, causing silent message loss
- [Bug]: v0.15.0 Docker image:The TUI cannot be used in the dashboard.
- cron: skip_memory=True blocks fact_store/memory tools from all cron jobs
- TUI: Node.js OOM crash when agent uses browser tools repeatedly
- feat: model_profiles — per-model toolset and memory config
- Automatic background skill patching disrupts active sessions (severe impact on local models)
- ensure_hermes_home() creates root-owned dirs in profile subdirectories when kanban workers are dispatched
- Feature: opt-in webhook bypass for DISCORD_ALLOW_BOTS — allow operator-initiated probes without weakening bot-loop guard
- v0.15.0: Codex requests fail HTTP 400 when participant display_name contains non-ASCII (emoji breaks input[].name pattern)
- Architecture: State Persistence Precedence (Memory vs Skills vs Hooks)
- [Bug]: cronjob tool: create action always fails with "schedule is required for create" even when parameters are provided
- codex-oauth: 'NoneType' object is not iterable in _run_codex_stream (gpt-5.5) — every turn fails non-retryably
- Docs/Config: Plugin local scope enablement ambiguity
- [Bug]: CLI freezes after using /new command (WSL)
- Profile Codex auth can ignore global credential pool when local state is stale
- [workflow-engine] CRITICAL: variable substitution crashes on regex metachars in user input
- [workflow-engine] HIGH: loop and bash nodes leak subprocesses on timeout
- [workflow-engine] HIGH: README documents config env vars the engine never reads
- [workflow-engine] MEDIUM: workflow_run rate limit bypassable via concurrent calls (TOCTOU)
- [workflow-engine] chore: manifest gaps, side-effectful register(), dead code, unauth kanban dispatch
- [mcp_lazy] HIGH: synthetic mcp_server_<name> stub collides with a real MCP server named 'server'
- [mcp_lazy] HIGH: promote_server eager flag documented but never persisted
- [mcp_lazy] MEDIUM: _prev_mode dict leaks and goes stale; not cleared on session evict
- [mcp_lazy] MEDIUM: get_pool has unlocked check-then-set race on pool creation
- [mcp_lazy] MEDIUM: pre_tool_call gives no guidance for unpromoted server-stub calls
- [mcp_lazy] chore: undeclared pre_tool_call hook, nonexistent 'mcp_load_tools' name in docs, missing tests
- [a2a_fleet] CRITICAL: server never auto-starts — register() runs outside an event loop
- [a2a_fleet] CRITICAL: auth_required defaults to false on a cross-machine surface
- [a2a_fleet] HIGH: remove invented disable() hook — loader never calls it, port leaks on reload
- [a2a_fleet] HIGH: plugin.yaml missing kind / provides_tools / requires_env (token env undeclared)
- [a2a_fleet] MEDIUM: tighten wide-open CORS, anonymous /health peer leak, and peer-URL SSRF
- [a2a_fleet] MEDIUM: relocate tests to tests/plugins/ and cover sync-register + auth-default paths
- xai-oauth auxiliary client incorrectly uses Responses API (CodexAuxiliaryClient), causing 403 on compression/vision/web_extract
- [Bug]: Direct Copilot gpt-5.5 large resumes are killed by 12s Codex TTFB watchdog
- [Bug]: `hermes uninstall` does not work on Windows
- TUI: Thinking block leaks raw JSON and Σ character
- Hostinger VPS: migration Hermes Agent → Hermes WebUI impossible (tini + UID mismatch + sessions)
- /goal judge over-continues exploratory goals unless the assistant explicitly says the goal is complete
- /goal auto-continuation can be amplified by preflight compression/session split and resurrect stale task state
- Dashboard infinite reload loop in loopback mode — GET /api/auth/me returns 401 on every page load
- [Bug]: Provider/LLM switch leaves stale encrypted_content causing 400 errors on Telegram sessions
- [Bug]: Infinite reload loop / React state loop on Sessions tab (Firefox + Chrome) — repeated 401 on /api/auth/me (v0.15.0)
- show_reasoning should work independently of streaming in CLI mode
- Feature Request: Strip reasoning/<think> blocks from TTS preprocessing
- mcp add / mcp test raise NameError when mcp package not installed
- v0.14.0 dashboard breaks behind reverse proxies — two regressions
- Skills hub creates empty category directories when no skills installed
- [Bug]: Custom endpoint: ChatCompletions returns content, but Hermes treats response as empty (v0.14.0)
- fix: atomic_replace() fails with EXDEV when HERMES_HOME is a cross-filesystem symlink
- fix(gateway): Feishu session cancellation orphans session guard, permanently blocking messages
- Custom endpoint pricing can overestimate Crof qwen3.5-9b cost by 1,000,000x
- MCP OAuth callback: module-level port global causes port collisions and structural weaknesses vs upstream
- Bug: send_message tool bypasses validate_media_delivery_path security check
- Proposal: Add Mnemosyne to official memory provider documentation
- feat(swarm): support custom verifier/synthesizer body + skills
- Template conversion failed
- Error occurred in the operation of the agent node in the workflow.
- PubSub client overrides Sentinel client when REDIS_USE_SENTINEL is enabled
- Frontend description of the Retrieval node output does not match the actual output
- JSON type input var raise Intenal server error
- cannot extract elements from a scalar
- 负载均衡 为模型配置多组凭据,并自动调用,此功能无法选择
- add models is error
- panic: could not create filter
- Persist partially generated messages when /chat-messages/:task_id/stop is called
- MCP server connection fails with 403 — request never leaves Dify (SSRF proxy suspected)
- Support durable async execution backends for long-running workflow steps
- [Xiaomi MiMo] Credentials validation fails with 400 "Not supported model mimo-v2-flash" when using Token Plan endpoint (v0.0.7)
- After clicking preview on a parent-child segmented knowledge base, it shows 0 chunks
- Retrieval score differs between UI upload (.docx) and API upload (.txt) despite identical chunk content and embedding model
- gemini cli crash again
- Xbox gift card code damage
- Damage caused by the gemini cli crash
- ioctl(2) failed, EBADF (Bad File Descriptor)
- Feat: Support Bun as an alternative runtime/package manager for updates and extensions
- fatal error again!!!!
- ioctl error
- Critical Crash: ioctl(2) failed, EBADF in ShellExecutionService.resizePty
- ioctl(2) failed, EBADF
- v0.44.0 Regression: Critical crash with ioctl(2) failed, EBADF during PTY resize
- Crash on startup: ioctl(2) failed, EBADF in UnixTerminal.resize
- Crash: `ioctl(2) failed, EBADF` in `node-pty` during PTY resize on macOS
- Gemini CLI crashes with `ioctl(2) failed, EBADF` in `node-pty` during `resizePty`
- Remote Role
- ERROR ioctl(2) failed, EBADF /home/mich
- RangeError: Maximum call stack size exceeded
- EBADF Error during folder creationg broke session and terminal glitches
- MAIP / Gargoub Project - Mediterania - North Coast
- Gemini cli crash again in this morning
- ERROR ioctl(2) failed, EBADF
- Verified node install fails — Checksum verification failed (Cloud)
- The extended debugging key did not arrive during registration.
- CollaborationPane unmounts collaboration store on single-user instances, causing permanent "No network connection" state
- Workflow cannot be saved when the name contains "->" (Potentially malicious string)
- automation does not work and does not show an error
- Raj Ai Automation
- Default Data Loader: DOMMatrix is not defined error
- Feature: Per-node execution timestamp overlay on canvas during workflow run
- AI Agent + Vertex `gemini-3.5-flash`: 400 "missing thought_signature" on sequential multi-turn tool calls (post-#24982)
- PDF Loader in Pinecone Vector Store fails due to pdf-parse version conflict (v2 not supported)
- emailReadImap: add UID deduplication, batch size cap, and numeric uid enforcement
- Manual node execution fails with "Could not find a node" when autosave is disabled (N8N_WORKFLOWS_AUTOSAVE_DISABLED)
- Schedule Trigger stopped firing — workflow Published & active, manual executions succeed, no automated fires for 2+ hours
- [MCP SDK] create_workflow_from_code intermittently returns HTTP 500, often as a false negative (workflow persists anyway, causing duplicates on retry)
- Credential-load wedge: workflows using googleApi/jwtAuth credentials silently fail to execute after key rotation
- Google Sheets Trigger every minute is not working manual Execute is working sent email
- [BUG] Plugin marketplace MCP connector remains stuck "still connecting" when mcp-remote requires OAuth
- [redacted at user request]
- Opus 4.7 behavioral regression: loaded instruction-following discipline degraded in recent Claude Code/Cowork updates
- [BUG] Tailscale via Homebrew CLI + Mac App Store GUI, both Macs on macOS, Cowork blocked by VPN detector despite Tailscale being a mesh VPN with no traffic interception
- stopShellPty on tab switch kills active sessions (exit 143) — regression in May 27 build
- [BUG] Long URLs are broken into multiple lines and become unclickable in terminal output
- [BUG] claude rm/stop/reap SIGKILLs background session tree without SIGTERM grace, orphaning git index.lock and similar
- [BUG] Default git workflow in the system prompt was pushed without context or consent
- [MODEL] Inconsistent output quality / Ignoring instructions (overfitting and inappropriate repetition of Korean vocabulary)
- You've hit your weekly limit · resets May 31 at 5pm (Asia/Shanghai)
- Paid yearly subscription silently downgraded to Free with no user action
- [Regression v2.1.153] Plugin bash hooks fail with "echo: write error: Permission denied" on Windows (claude-mem, shell: "bash")
- [BUG] Connector toggles in conversation are not clickable — must click text label instead
- [remote-control] Input from mobile app/browser not reaching host session — output works fine
- Model fails to read/reference CLAUDE.md contents despite being loaded in context
- [BUG] Claude Desktop reinstall destroys Code chat history (transcripts + Recents) while regular Chat history, project files, and memory all survive
- Bypass mode clamps to Accept Edits even with the toggle ON (Claude Code Desktop 1.9255.2 / CC 2.1.149)
- [BUG] TUI input freezes randomly mid-typing — entire prompt becomes unresponsive for minutes
- [BUG] Cowork downloads Linux ELF binary instead of macOS binary on macOS Sonoma 14.8.7 — exit code 132 (SIGILL) on every session
- [Feature Request] Persistent project memory — sessions forget everything on close, forcing users to keep many sessions open
- [Bug] Thread context stale after sleep/resume, returns outdated date and calendar data
- [FEATURE] Add context window usage indicator and warning before auto-compaction
- [BUG] Dictation error: Invalid character in header content ["x-config-keyterms"] on Windows
- [Bug] Anthropic API Error: Server rate limiting despite normal usage
- Does delegating work to `claude -p` subprocesses reduce context accumulation in the parent session?
- [BUG] Claude Code hangs on M1 Mac when terminal says "opening browser to sign in" and browser opens
- [BUG] Claude_Preview MCP preview_start spawns dev server with main-repo cwd instead of session's worktree cwd
- [Bug] Anthropic API Error: Server rate limiting during request execution
- [Bug] Anthropic API Error: Server rate limiting on concurrent requests
- [Bug] Ultraplan ready notification fires before cloud agent completes execution
- [BUG] API 500 ERROR ALL THROUGHOUT THE DAY
- [BUG] Cowork: Live Artifacts folder path changed in 1.9255.2, no automatic migration from Documents\Claude\Artifacts
- [Bug] Auto-compact never triggers despite statusline reporting "100% context used" (v2.1.153, Max sub, 200K mode)
- [BUG] [Desktop / macOS] 'Open in → New Window' detached session: font renders smaller than main, no per-window controls, Cmd+/Cmd- keystrokes routed to main window instead
- Feature request: option to switch between classic and new minimal UI
- [Feature Request] Show timestamps for each message
- [BUG] Terminal corruption when permission prompt appears while navigating Agent Teams agent selection menu
- [FEATURE] Allow users to customize the background color of the Claude desktop app beyond the current light/dark theme presets.
- [BUG] Statusline not displaying on Windows [fixed]
- Background agent UI Stop button is a no-op for stuck agents — process keeps consuming tokens
- Background agents silently die on session pause/resume — no completion notification, no work recovery
- Add option to hide email address from welcome banner
- [BUG] SSH Remote: `projects` field in remote ~/.claude.json becomes null after desktop restart — jsonl files intact, UI shows 'No messages yet' for every session
- [Bug] Claude Code not applying fixes despite claiming to complete tasks
- billing is unfair and poorly documented
- [BUG] Claude Code on the web: declared plugins inactive on first session, require restart to fully load
- [BUG] Restore from archive deleted sessions instead of restoring them
- [BUG] M365 connector fails with AADSTS50011 in Cowork — localhost vs 127.0.0.1 redirect URI mismatch
- claude agents: workflow slash-commands missing from dispatch-input completion (regression-adjacent to #61424)
- Claude Desktop's Info.plist missing TCC usage strings, blocks all EventKit-based MCP servers
- False-positive safety blocks on self-administered governance amendments — request for owner-authority mode for verified professional users
- [BUG] Stop pushing "AUTO"-mode
- [DOCS] Plugin marketplace guide omits `skipLfs` option for git-based sources
- [DOCS] MCP docs omit combined startup notification for MCP server and connector authentication
- [DOCS] Agent view docs omit macOS Privacy & Security identity for background agents
- [DOCS] Npm update docs do not explain release-channel behavior for `claude update`
- [DOCS] Agent SDK docs omit `subagent_type: "claude"` worktree and output persistence behavior
- [DOCS] Background session docs omit `$CLAUDE_JOB_DIR` temp-file behavior
- [FR] mask env-var values in 'claude mcp get <server>' output
- [FR] subagent worktrees should not inherit stale local 'user.email' from prior dispatches
- [BUG] Windows: Grep tool leaks rg.exe + conhost.exe processes (~2000 zombies / 14 GB RAM in long sessions)
- [BUG] Stats dashboard "Peak hour" appears off by one hour
- [BUG] Diff highlight (teal SGR background) bleeds past changed text in 2.1.150–2.1.153
- [FEATURE] confirm before deleting session
- Plugin PostToolUse hooks still silently skip in Claude Desktop / Cowork (re-filing closed #51904)
- /code-review skill: silent fallback to main...HEAD reviews other people's commits, and JSON-only output is hard to read
- Monitor tool doesn't source the shell snapshot like Bash does; PATH-dependent tools (jq, sleep, etc.) fail in Monitor commands on macOS/Nix
- [Bug] Long input lines truncated with ellipsis while typing instead of wrapping in terminal UI
- [FEATURE] VS Code extension: Render submitted user messages as Markdown in chat
- OSC 52 copy from Claude TUI doesn't reach clipboard inside tmux (regression in 2.1.146–2.1.153)
- [BUG] RemoteTrigger create/update returns HTTP 400 with circular error: "event_type is required" / "unknown field event_type"
- [BUG] Option to hide or minimize the built-in "status footer" (multi-line debug/cost panel) [re-raise of #31475]
- [Bug] Feedback submissions being closed without review or action
- [FEATURE] Word-jump cursor navigation in Chat input (option+arrow / bindable actions)
- [FEATURE] ! shell mode: filesystem tab completion
- [BUG] API Error: Usage credits required for 1M context
- claude agents: OSC 52 clipboard emission broken in tmux (regression in 2.1.146–2.1.153)
- CLI crashes on macOS 15 M3 - exit code 1
- [FEATURE] Support Cmd+V image paste from clipboard
- [FEATURE] Enhance claude.ai M365 connector to support MS Planner
- [BUG] Slash command autocomplete hijacks pasted absolute file paths starting with /
- PreToolUse hook `if` filter false-positives on complex Bash commands
- [BUG] Diff panel hangs/whites out
- Feature Request: Support drag-and-drop for binary documents (.wps, .doc, .docx, .xlsx, .pdf) in VS Code extension
- [BUG] activation of 1M context in VSCode
- [FEATURE] Support i18n / language localization for built-in slash command outputs
- Ctrl+V para colar imagens deixou de funcionar no CLI (Windows, PowerShell)
- [FEATURE] Please add Norwegian (Bokmål/Nynorsk) language support to the Claude Code interface
- [BUG] OTel log events (claude_code.user_prompt, api_request_body, tool_decision, hook_execution_complete) emitted with empty trace_id/span_id while sibling spans correlate correctly
- [BUG] Cowork crashes on every message, no VM logs generated, missing AppData\Roaming\Claude
- [FEATURE] first-class session handoff + per-session token budgets for unattended runs
- [FEATURE] Smart paste: convert clipboard code to file reference chips (like Cursor)
- [Feature Request] Restore chat pin functionality to title chat submenu
- [BUG] SIGILL issues with version 2.1.153
- [BUG] Cowork plugin upload fails with generic "Plugin validation failed" when a `description` field in any SKILL.md frontmatter contains angle brackets (`<…>`)
- [BUG] Desktop App 2.1.144+: startup scanner deletes cliSessionId from claude-code-sessions local files on every launch — session not found on disk
- [Feature Request] Add keyboard shortcut to copy last message with proper formatting
- [MODEL] Opus 4.7 not 1M
- Allow naming/renaming background agents in `claude agents` view
- Stale worktrees in .claude/worktrees/ are never cleaned up, consuming massive disk space
- Agent worktrees are never cleaned up, silently consuming disk space
- Subagent worktrees not auto-cleaned when reviewer writes scratch files
- [Bug] Skill initialization hangs for extended duration in Plan Mode
- Claude Desktop writes malformed registry Run entry (nested escaped quotes) - crashes Windows Task Manager and other Run-key parsers
- IME candidate window shows at bottom-right corner instead of caret position (Windows CMD)
- [BUG] Pressing 'Escape' doesn't close the /BTW conversation when the main conversation is asking for approval
- [BUG] Opus 4.7 (1M) intermittently emits empty-string values for tool_use.input fields, killing the session
- FleetView agent UI shows "running" with incrementing elapsed time after agent has returned
- /doctor flags context-scoped cmd+c binding as macOS conflict (false positive)
- [BUG] Text Rendering in Elvish
- Desktop app: Bypass Permissions mode flips to Accept Edits on first prompt (M5 / macOS 26.5)
- [Workaround] Date-Weekday Verification Hook — Prevents Claude from writing wrong weekdays
- [BUG] Claude Code create c:/memfs directory without asking me.
- [BUG] Claude Code's Bash execution waits forever with no processes running
- [BUG] usage stays stuck waiting for 5 hr limit after upgrading to premium seat in team plan
- [Workflow tool] resume cache is unreachable for nontrivial workflows because LLM dispatchers can't transcribe args byte-exactly
- Code review (Preview): "Add a repository" shows no results for private GitHub org repos
- [BUG] /context commands blows up context
- [Feature Request] Add precache expiry hook to enable proactive compaction before token eviction
- [BUG] Context indicator shows 0% at session start despite ~20K+ tokens already loaded
- [Feature Request] Add semantic search for --resume session history
- [Feature Request] Add session search, tagging, and filtering capabilities
- [BUG] Cowork Dispatch reports "desktop not available" on Windows 11 while standard Cowork works normally
- [Bug] Claude Code provides incorrect suggestions with high confidence despite errors
- defaultMode: acceptEdits silently overrides per-path permissions.ask rules for Write/Edit
- [FEATUR configurable tip interval (e.g. tipIntervalSeconds: 30 in settings)E]
- Plugin marketplace fails to load: schema rejects 'displayName' key (v2.1.153)
- claude agents: in-session copy uses broken OSC 52 path while overview correctly uses tmux buffer
- [BUG] Plugin agent descriptions (and custom agents) load unconditionally into context — no parity with disable-model-invocation for skills
- Crashed ultrareview consumed a free credit despite producing zero findings
- [Bug] Character rendering issue - invisible or missing text display
- [BUG] Cowork: processo Claude Code encerra com código 3 — .claude.json não contém token de autenticação (Windows 11 25H2)
- [BUG] 2.1.153 silently discards tools/list response from rmcp 0.12.0 HTTP MCP server (works in 2.1.152, wire-identical handshake)
- VS Code extension: option to auto-resume last session when reopening a workspace folder
- [Bug] Conversation continuation failure
- [BUG] Cowork crashes every time I start a new chat or attempt to continue an existing one in any project. The error displayed is: "Claude Code è andato in crash
- [Bug] Unannounced quota changes
- Native update/install fails with 'socket connection was closed unexpectedly' behind proxy — undici TLS incompatibility
- [BUG] Session name reverting after manual change
- [BUG] 非正常思考,上下文过长时,一直显示思考,点击interrupt按钮失效
- Honor `tools:` frontmatter when an agent is invoked via `@mention` — strip `Task` only when the agent did not declare it
- macOS TCC popup still recurring on v2.1.153 — "2.1.153" would like to access data from other apps
- Claude Code leaks pty handles — exhausts pseudo-terminals on macOS after long session
- [Bug] Agent fails to execute or respond to user input
- [BUG] Persistent "Expecting value: line 1 column 1 (char 0)" JSON parse error after tool execution
- [Feature Request] Implement proactive unit test coverage recommendations for recurring bugs
- VS Code panel lacks status line + terminal lacks image paste in Codespaces, forcing a tradeoff
- `/powerup` only shows ~10 lessons — allow viewing the full catalog
- [Bug] Context contamination after auto-compact with unrelated email draft of Tejo/Sado Basin
- [Bug] VSCode terminal output displays corrupted text with garbled symbols
- [Feature Request] Add LaTeX/KaTeX math rendering to TUI
- [Bug] Sub-agent PR review results not validated by orchestrating agent
- Subagents on Pro 1M tier: trivial probes pass, real workloads fail at first tool call (probe-vs-workload divergence)
- Path-scoped rules and subdirectory CLAUDE.md not loaded when creating new files matching the pattern
- AskUserQuestion: cancelling during extended thinking poisons the whole session with 400 'thinking blocks cannot be modified' (2.1.153); concurrent prompts overwrite each other
- Ideas Missing from Claude Cowork Menu (Windows)
- [BUG_BOUNTY_SAFE_POC_2026] Prompt Injection RCE Test - Command Execution Proof
- [BUG] Cowork scheduled task: execution history row not showing after successful run
- Resuming an extended-thinking session fails permanently with 400 "thinking blocks cannot be modified" (transcript stores thinking text as empty but keeps signature)
- [Bug] Plugin-registered CwdChanged and FileChanged hooks don't fire (settings.json works) — v2.1.153
- Auto-archive on PR merge / branch delete — clarify autoArchiveSessions semantics or add dedicated opt-out
- `claude mcp add` echoes Authorization header value verbatim to stdout, leaks bearer tokens to terminal and session transcripts
- [BUG] Bug report — /insights skill, Claude Code The /insights skill outputs a malformed file path.
- Plugin slash commands render with '*'-inline format instead of two-column, despite matching official plugin shape
- [Bug] Unexpected long text generation without user input or goal
- [Bug] Thinking blocks causing task progression blocked without user modification
- [BUG] (Critical!) contamination by an unknown session simirlar to the report => [Bug] Context contamination after auto-compact with unrelated email draft of Tejo/Sado Basin #63137
- [Critical] Opus 4.7 Korean output degeneration — Korean grammar itself collapses in long contexts
- [BUG] Title: Autocompact buffer persists across /clear — wastes tokens for irrelevant old context
- [Bug] Auto-Compact loses user input before processing in conversation history
- Feature: per-invocation effort parameter + runtime session-config introspection for skills
- Auto-mode classifier mislabels Azure DevOps vote -5 as "Reject" when denying PR vote actions
- [BUG] Claude Desktop and Claude Code CLI never re-register MCP tools after OAuth 2.1 handshake on a remote HTTP server
- [BUG] Workspace file tags leak across sessions
- [BUG] Ink renderer crashes on Windows 11 build 26200 (Canary) duplicate banners, terminal mode leaks, mid-operation aborts
- [BUG] Claude Code Desktop issue
- PTY master fd leak in Claude desktop app exhausts macOS kern.tty.ptmx_max after ~2-3 days
- [BUG] Claude Code — Session Management after Unexpected Interruption
- [Windows] Cowork OpenTelemetry exporter does not initialize - zero events emitted to any destination, including loopback
- [Bug] Opus 4.7: 400 `thinking blocks ... cannot be modified` on long extended-thinking sessions, triggered by history-altering events (scheduled prompts / parallel tool-call cancellation)
- [BUG] API Error: Server is temporarily limiting requests (not your usage limit) · Rate limited
- Multi-plugin custom marketplace: only first plugin registered in installed_plugins.json, skills don't load
- [BUG] Git push through the SDK's git proxy fan-outs into ~500 GitHub REST API calls, exhausting the 5,000/hour budget after a handful of pushes
- [BUG] Claude took liberties it really shouldn't with my global config
- [BUG] Agent window focus lost after navigating with arrow keys, causing scroll deadlock
- [BUG] `--model` flag silently ignored in interactive sessions (works in `--print` only)
- [BUG] Dispatch permanently shows "desktop appears offline" on Windows 11 - never worked on first use
- feat: support per-command enableWeakerNetworkIsolation as safer alternative to dangerouslyDisableSandbox
- /code-review outputs a raw JSON array instead of readable findings
- [BUG] Cowork — Additional allowed domains ignored on Team plan; same domain works on Pro plan
- Haiku
- [Bug] False positive blocking beneficial outcomes in tool execution
- 3P Bedrock SSO: credentials silently expire without triggering re-auth on day 2+
- CLAUDE_AUTOCOMPACT_PCT_OVERRIDE in settings.json env block silently ignored by autocompact logic
- Auto-compaction deletes main session JSONL before verifying summary completion, causing data loss
- [Bug] Claude Code not executing stated actions or producing expected results
- [FEATURE] Deferred Messages — Queue Input for End of Turn
- [BUG] Up/Down arrows in input box navigate history instead of moving cursor — regression in 2.1.149+
- Cancelling a parallel tool-call batch corrupts thinking blocks -> 400 "thinking blocks cannot be modified" permanently wedges the session
- Claude Code caused data loss, then contradicted itself about recovery (two incidents, one session)
- [Bug] Unclear error messages from Claude Code CLI
- [Bug] Agent tool rejecting due to context size limit exceeded
- claude agents: daemon and bg-spare processes spin at ~100% CPU when idle
- [BUG] Compaction fails with "context window limit" error even when context usage is low (e.g., 20%) — regression in v2.1.153
- Remote Control entitlement lost after May 27-28 incident — `Error: Remote Control is not yet enabled for your account` on active Max subscription
- PreToolUse hook exit code 2 does not block Write tool
- [Bug] Thinking blocks in latest assistant message are immutable
- GUI: dispatch file:// and custom-scheme clicks to OS shell handler
- Show current model in statusLine by default
- [Bug] Agent console becomes unresponsive to keyboard input after multiple agents initialized
- [FEATURE] PreToolUse hooks should have a way of updating the environment
- [Bug] Unable to start or use Claude Code CLI
- [BUG] Repository not visible in Claude Code web repo picker
- Session permanently wedged on 400 "thinking blocks cannot be modified" after parallel tool_results
- [Bug] @ autocomplete loses sibling repos after a file edit in multi-repo workspace
- Unclear error message when creating sub-agent without authentication
- [Bug] Anthropic API errors causing frequent failures and high token usage
- [BUG] @ mention file picker only shows packages, not individual files (desktop app - Code tab)
- [Bug] TUI panel footer remains sticky and consumes excessive terminal space
- PR-status polling exhausts GitHub GraphQL rate limit on repos with many open PRs
- [BUG] Windows: welcome panel not shown in some project folders (2.1.153)
- [Bug] Anthropic API Error: thinking blocks corrupted during context compaction with extended thinking enabled
- API 400 "thinking blocks cannot be modified" permanently bricks session during agent activation (interleaved thinking + tool use)
- Right-click Copy copies the whole message instead of the selection; pasted text retains dark background
- Mid-session model switch corrupts conversation when extended thinking is enabled (API 400: 'thinking blocks cannot be modified')
- [BUG] Markdown file links in chat output do not open files when clicked (VS Code extension)
- Stuck retry loop: `400 thinking blocks cannot be modified` on large interleaved-thinking turns using AskUserQuestion
- [FEATURE] Prompt user for approval before auto-compaction proceeds
- Custom MCP connectors not attachable to scheduled routines — no UUID discovery path
- [BUG] Claude in Chrome — Navigation blocked for teams.cloud.microsoft and outlook.cloud.microsoft after Microsoft domain migration**
- [BUG] Claude Desktop — Personal plugins panel renders list but is entirely non-interactive (macOS, v1.9255.2)
- [Bug] error when using Workflows
- [BUG] Persistent "update available" notification despite being on latest version
- [BUG] Sweep Agent from /code-review never completes
- [Bug] Tool calls not executing or returning results
- [FEATURE] Cloud-synced memory and settings across machines
- [Bug] Terminal UI freezes when Ctrl+O view exits during interactive prompt in plan mode
- Continuous api errors when using claude code with Opus 4.7 with thinking on low
- [Feature Request] Add support for installing and using previous Claude Code versions
- [Bug] Extended Thinking: Summarized thinking blocks fail signature validation when resent to API
- [Bug] Anthropic API Error: 'thinking' blocks cannot be modified
- [Bug] Anthropic API Error: Thinking blocks cannot be modified with extended thinking mode
- Feature request: Lazy/on-demand MCP server connections
- [Bug] Tool Arguments Parsed as String Instead of Object
- [Bug] Anthropic API Error: Insufficient context provided
- [Bug] Claude Opus occasionally uses moskovian(russian) orthography instead of Ukrainian in system-prompted responses
- Opus 4.8: backgrounded task completions (subagents AND Bash) crash with 400 "thinking blocks cannot be modified"
- [Bug] Opus 4.7 fabricates stable preferences ("my default") to rationalize arbitrary choices when challenged
- [Bug] Unable to update Claude Code CLI
- [BUG] Desktop app: /remote-control mints link + connects bridge (main.log) but in-chat link/QR panel never renders
- Feature: sessionColor and sessionName in .claude/settings.json
- [BUG] Anthropic API error: thinking blocks
- [FEATURE] Support Remote MCPs in Cowork as in Claude Code
- [Bug] Anthropic API Error: 400 Bad Request with Redacted Thinking - 0 4.7 & 4.8
- [Bug] Anthropic API Error: Cannot modify thinking blocks from different model versions
- Interleaved thinking + multi-tool turn corrupts thinking block (text blanked, signature kept) → permanent 400 'blocks must remain as they were'
- [BUG] Mode/permission changes mid-tool-loop (effortLevel: xhigh) poisons entire session
- Session failure log: Opus 4.6 ignores its own rules for an entire session
- [BUG] "400 Guardrail was enabled" error when using Claude Opus 4.8 with AWS Bedrock
- [Feature Request] Add subagent approach selection option to avoid accidental feedback
- Persistent 400 'thinking blocks in the latest assistant message cannot be modified' — interleaved thinking persisted with empty text + signature bricks sessions
- [BUG] DesktopvsApp
- [BUG] Opus 4.7 cache hit rate collapse after May 27 incident — Messages 1.1k→88.9k in 9 minutes, $630/session
- [Bug] Anthropic API Error: Invalid thinking block format
- [BUG] FUCK CLAUDE
- Opus 4.8 extended thinking: Stop hook block re-entry corrupts thinking blocks → 400
- [Bug] 4.8 Fails when accessing previous model history
- [Bug] Unintended File Modifications During Execution
- [DOCS] Model configuration docs omit lean system prompt default scope and model exceptions
- Add "Always allow globally" option to permission prompts
- Server-side model upgrade (Opus 4.7→4.8) wedges in-flight sessions with `thinking blocks cannot be modified` 400
- [DOCS] AskUserQuestion docs missing multiple-choice prompt decision threshold
- [DOCS] Agent view docs omit shell-command background session launch syntax
- [DOCS] Agent view dispatch input docs incorrectly imply `/logout` dispatches as a prompt
- [DOCS] Claude in Chrome docs omit connected-browser selection behavior
- [DOCS] Plugin docs omit `defaultEnabled: false` for opt-in plugins
- Feature Request: Customizable chat text colors for user and assistant messages
- [DOCS] `/plugin` Discover tab docs omit directory-based suggested plugin pins
- VSCode Chrome integration silently fails: 3 distinct bugs
- [DOCS] MCP stdio docs omit session environment variables
- [Bug] Anthropic API error on second request within session with Claude Opus 4.8
- Cowork emits a blank session "index" handoff on focus when a CLI session is paused awaiting input
- [DOCS] MCP docs omit `claude mcp list/get` pending-approval output for unapproved project servers
- [BUG] /compact fails with 400 error when last assistant turn contains thinking blocks
- [DOCS] `/claude-api` docs omit Opus 4.8 migration guidance
- [DOCS] Fast mode docs still recommend deprecated Opus 4.6 override variable
- [DOCS] Bash tool docs omit `$TMPDIR` consistency across sandboxed and unsandboxed commands
- [Bug] Anthropic API Error: 400 Bad Request on Extended Thinking
- [DOCS] Background session docs omit worktree-isolation behavior for spawned subagents
- Built-in mechanistic self-verification of verifiable claims (symmetric to the auto permission gate)
- [DOCS] Worktree docs do not clarify `worktree.baseRef: "head"` inside linked worktrees
- [BUG] Excessive RAM usage with multiple parallel chats (~10 sessions → 30 GB memory pressure, macOS OOM)
- [DOCS] Managed MCP policy docs omit invalid `allowedMcpServers`/`deniedMcpServers` entry behavior
- [DOCS] Effort docs omit `CLAUDE_CODE_ALWAYS_ENABLE_EFFORT` unsupported-model behavior
- Regression (2.1.147–2.1.150?): resuming an extended-thinking session after a CC update/model-switch → unrecoverable 400, session bricked
- [DOCS] Windows updater docs omit `claude.exe` in-use recovery guidance
- [DOCS] VS Code auto mode docs still tie mode-picker visibility to bypass-permissions setting
- [DOCS] MCP docs omit `/mcp` tool list and detail rendering behavior
- [DOCS] Fine-grained tool streaming docs still describe provider opt-in behavior
- bypassPermissions: session startup reads flat pref, GUI toggle writes per-account pref — they never sync
- [BUG] Claude Desktop Code tab causes disk write limit violation — 8.5GB in 11 min, macOS kills app (M5, v1.9659.1)
- Ultrareview v2.1.96: docs describe /tasks command + claude ultrareview --json subcommand that don't exist; findings hard to read after completion
- I'd be happy to help create a GitHub issue title, but I don't see the error message in your message. Could you please share the specific error you're encountering? That way I can generate an accurate and descriptive issue title for you.
- [BUG] Claude in Chrome `file_upload` rejects all scheduled-task sessions with misleading error (real cause: INVALID_SESSION)
- Extended thinking: signed thinking block 'cannot be modified' (400) permanently wedges session
- RTL text support for Hebrew (and Arabic) in Claude Code
- [Bug] Random errors occurring across multiple operations